In my last post, I wrote about how I taught sesdev (originally a tool for deploying Ceph clusters on virtual machines) to deploy k3s, because I wanted a little sandbox in which I could break learn more about Kubernetes. It’s nice to be able to do a toy deployment locally, on a bunch of VMs, on my own hardware, in my home office, rather than paying to do it on someone else’s computer. Given the k3s thing worked, I figured the next step was to teach sesdev how to deploy Longhorn so I could break that learn more about that too.
Teaching sesdev to deploy Longhorn meant asking it to:
- Install nfs-client, open-iscsi and e2fsprogs packages on all nodes.
- Make an ext4 filesystem on
/dev/vdbon all the nodes that have extra disks, then mount that on/var/lib/longhorn. - Use
kubectl label node -l 'node-role.kubernetes.io/master!=true' node.longhorn.io/create-default-disk=trueto ensure Longhorn does its storage thing only on the nodes that aren’t the k3s master. - Install Longhorn with Helm, because that will install the latest version by default vs. using kubectl where you always explicitly need to specify the version.
- Create an ingress so the UI is exposed… from all nodes, via HTTP, with no authentication. Remember: this is a sandbox – please don’t do this sort of thing in production!
So, now I can do this:
> sesdev create k3s --deploy-longhorn
=== Creating deployment "k3s-longhorn" with the following configuration ===
Deployment-wide parameters (applicable to all VMs in deployment):
- deployment ID: k3s-longhorn
- number of VMs: 5
- version: k3s
- OS: tumbleweed
- public network: 10.20.78.0/24
Proceed with deployment (y=yes, n=no, d=show details) ? [y]: y
=== Running shell command ===
vagrant up --no-destroy-on-error --provision
Bringing machine 'master' up with 'libvirt' provider…
Bringing machine 'node1' up with 'libvirt' provider…
Bringing machine 'node2' up with 'libvirt' provider…
Bringing machine 'node3' up with 'libvirt' provider…
Bringing machine 'node4' up with 'libvirt' provider…
[... lots more log noise here - this takes several minutes... ]
=== Deployment Finished ===
You can login into the cluster with:
$ sesdev ssh k3s-longhorn
Longhorn will now be deploying, which may take some time.
After logging into the cluster, try these:
# kubectl get pods -n longhorn-system --watch
# kubectl get pods -n longhorn-system
The Longhorn UI will be accessible via any cluster IP address
(see the kubectl -n longhorn-system get ingress output above).
Note that no authentication is required.
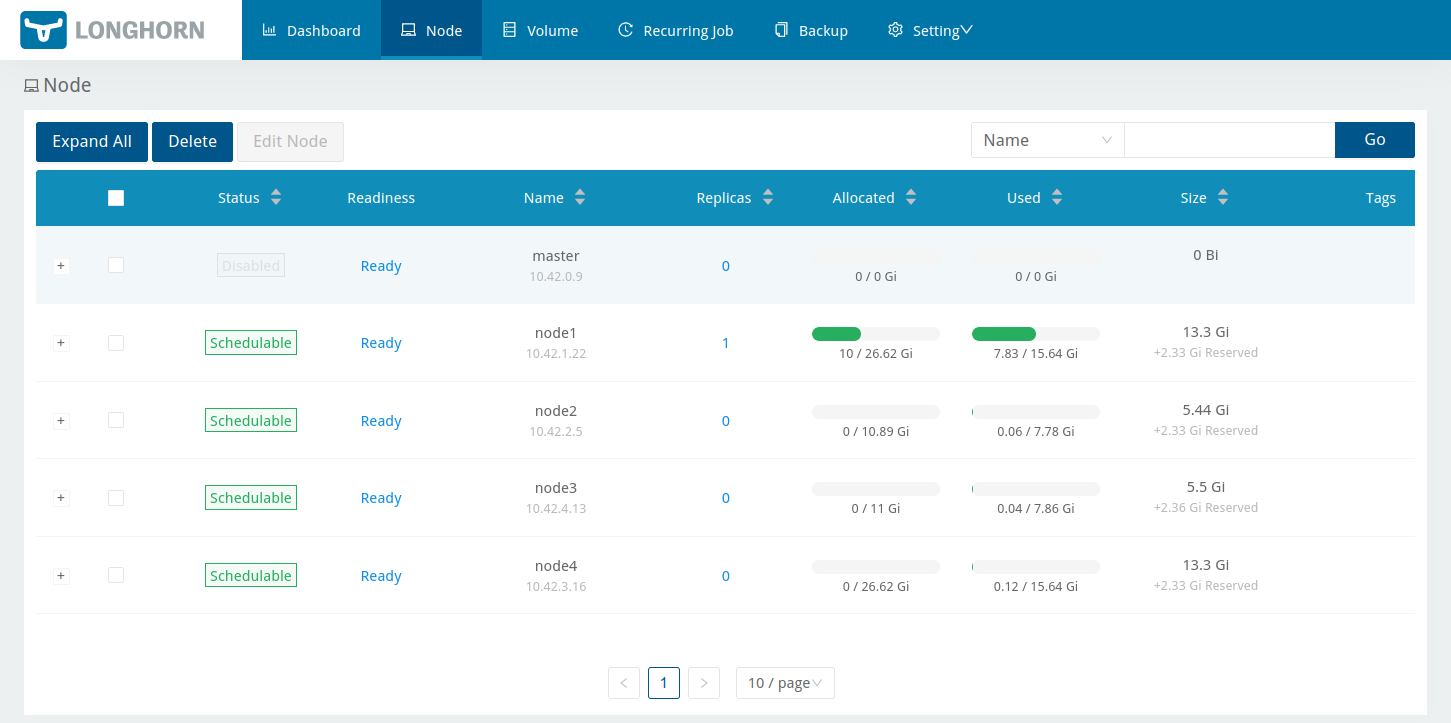
…and, after another minute or two, I can access the Longhorn UI and try creating some volumes. There’s a brief period while the UI pod is still starting where it just says “404 page not found”, and later after the UI is up, there’s still other pods coming online, so on the Volume screen in the Longhorn UI an error appears: “failed to get the parameters: failed to get target node ID: cannot find a node that is ready and has the default engine image longhornio/longhorn-engine:v1.4.1 deployed“. Rest assured this goes away in due course (it’s not impossible I’m suffering here from rural Tasmanian internet lag pulling container images). Anyway, with my five nodes – four of which have an 8GB virtual disk for use by Longhorn – I end up with a bit less than 22GB storage available:
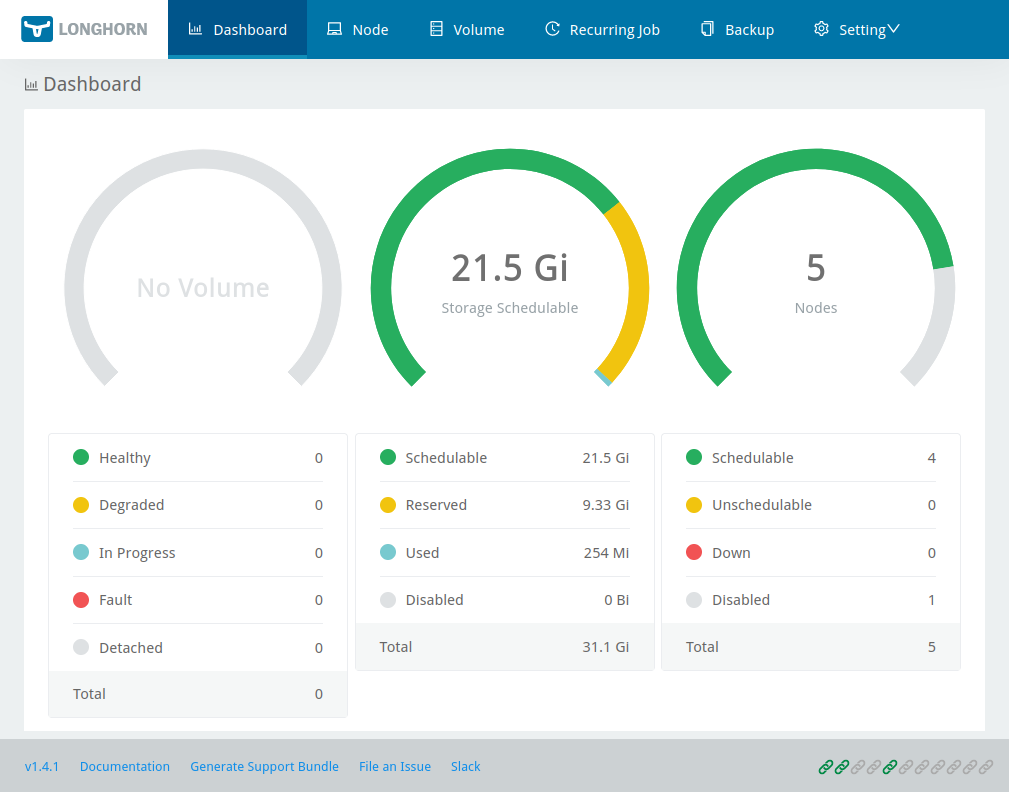
Now for the fun part. Longhorn is a distributed storage solution, so I thought it would be interesting to see how it handled a couple of types of failure. The following tests are somewhat arbitrary (I’m really just kicking the tyres randomly at this stage) but Longhorn did, I think, behave pretty well given what I did to it.
Volumes in Longhorn consist of replicas stored as sparse files on a regular filesystem on each storage node. The Longhorn documentation recommends using a dedicated disk rather than just having /var/lib/longhorn backed by the root filesystem, so that’s what sesdev does: /var/lib/longhorn is an ext4 filesystem mounted on /dev/vdb. Now, what happens to Longhorn if that underlying block device suffers some kind of horrible failure? To test that, I used the Longhorn UI to create a 2GB volume, then attached that to the master node:

Then, I ssh’d to the master node and with my 2GB Longhorn volume attached, made a filesystem on it and created a little file:
> sesdev ssh k3s-longhorn
Have a lot of fun...
master:~ # cat /proc/partitions
major minor #blocks name
253 0 44040192 vda
253 1 2048 vda1
253 2 20480 vda2
253 3 44016623 vda3
8 0 2097152 sda
master:~ # mkfs /dev/sda
mke2fs 1.46.5 (30-Dec-2021)
Discarding device blocks: done
Creating filesystem with 524288 4k blocks and 131072 inodes
Filesystem UUID: 3709b21c-b9a2-41c1-a6dd-e449bdeb275b
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Allocating group tables: done
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
master:~ # mount /dev/sda /mnt
master:~ # echo foo > /mnt/foo
master:~ # cat /mnt/foo
foo
Then I went and trashed the block device backing one of the replicas:
> sesdev ssh k3s-longhorn node3 Have a lot of fun... node3:~ # ls /var/lib/longhorn engine-binaries longhorn-disk.cfg lost+found replicas unix-domain-socket node3:~ # dd if=/dev/urandom of=/dev/vdb bs=1M count=100 100+0 records in 100+0 records out 104857600 bytes (105 MB, 100 MiB) copied, 0.486205 s, 216 MB/s node3:~ # ls /var/lib/longhorn node3:~ # dmesg|tail -n1 [ 6544.197183] EXT4-fs error (device vdb): ext4_map_blocks:607: inode #393220: block 1607168: comm longhorn: lblock 0 mapped to illegal pblock 1607168 (length 1)
At this point, the Longhorn UI still showed the volume as green (healthy, ready, scheduled). Then, back on the master node, I tried creating another file:
master:~ # echo bar > /mnt/bar master:~ # cat /mnt/bar bar
That’s fine so far, but suddenly the Longhorn UI noticed that something very bad had happened:

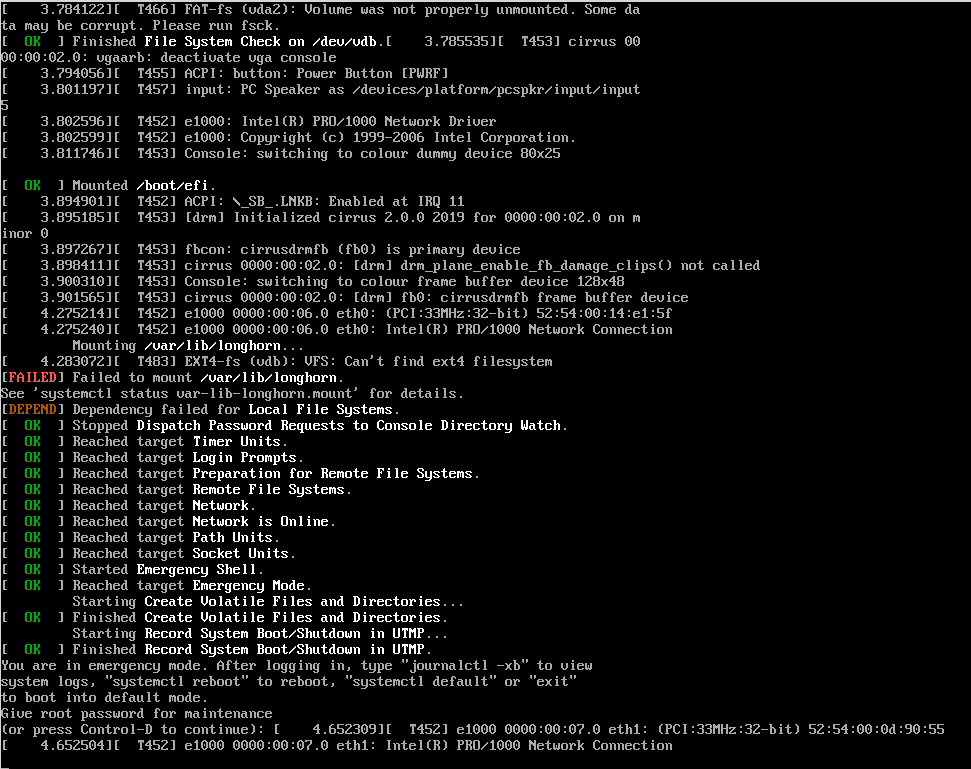
Ultimately node3 was rebooted and ended up stalled with the console requesting the root password for maintenance:
Meanwhile, Longhorn went and rebuilt a third replica on node2:
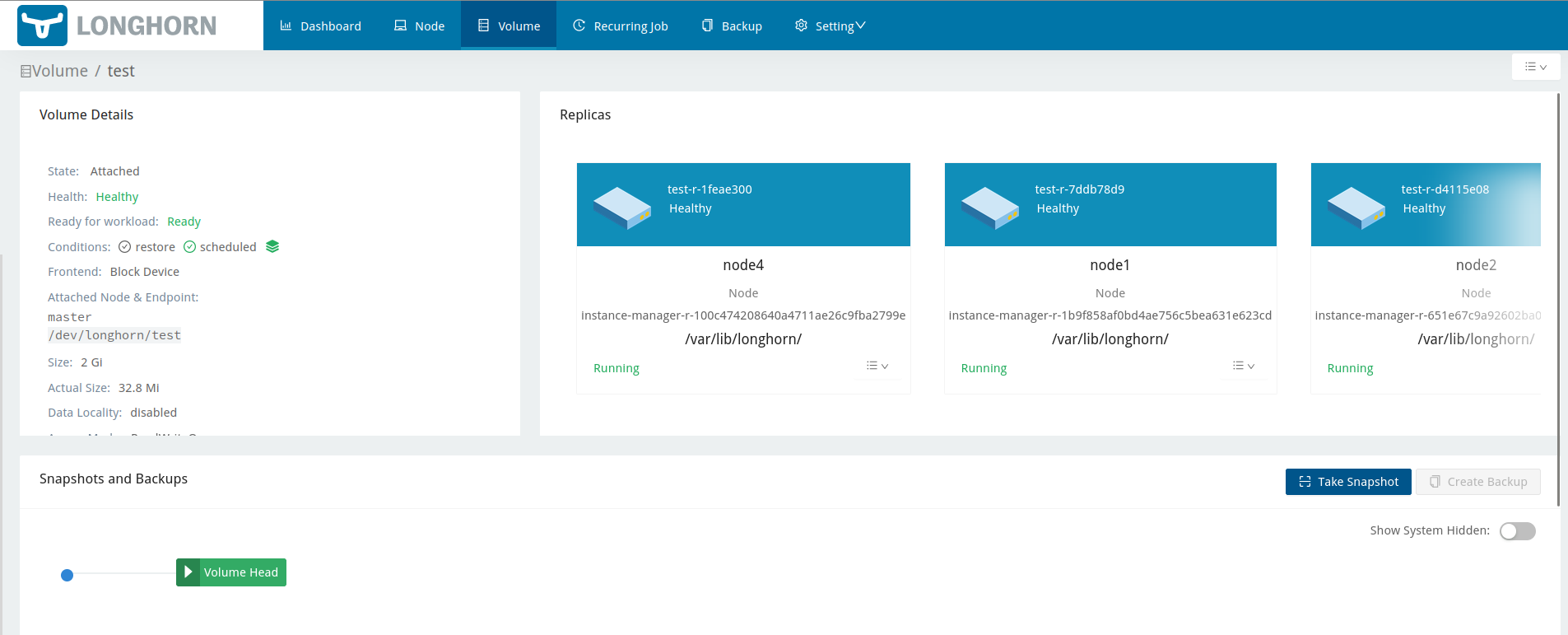
…and the volume remained usable the entire time:
master:~ # echo baz > /mnt/baz master:~ # ls /mnt bar baz foo lost+found
That’s perfect!
Looking at the Node screen we could see that node3 was still down:
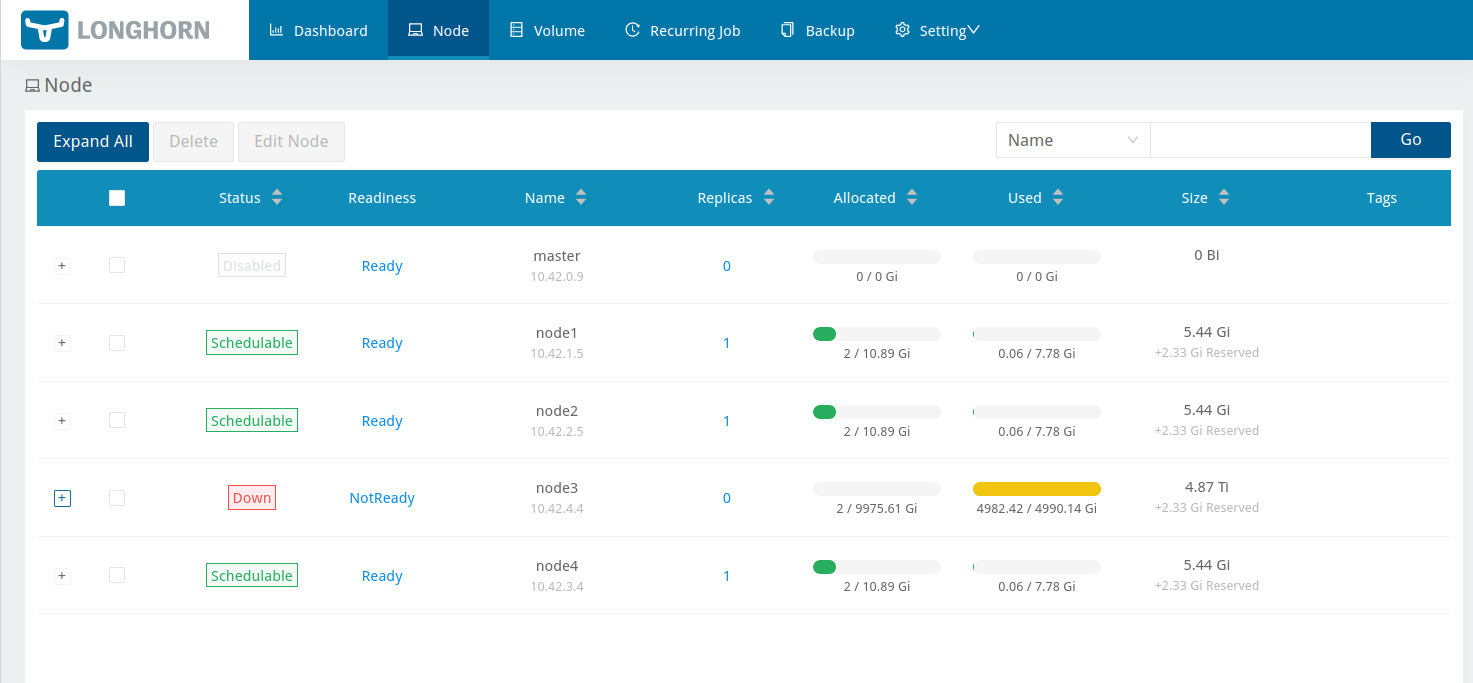
That’s OK, I was able to fix node3. I logged in on the console and ran mkfs.ext4 /dev/vdb then brought the node back up again.The disk remained unschedulable, because Longhorn was still expecting the ‘old’ disk to be there (I assume based on the UUID stored in /var/lib/longhorn/longhorn-disk.cfg) and of course the ‘new’ disk is empty. So I used the Longhorn UI to disable scheduling for that ‘old’ disk, then deleted it. Shortly after, Longhorn recognised the ‘new’ disk mounted at /var/lib/longhorn and everything was back to green across the board.
So Longhorn recovered well from the backing store of one replica going bad. Next I thought I’d try to break it from the other end by running a volume out of space. What follows is possibly not a fair test, because what I did was create a single Longhorn volume larger than the underlying disks, then filled that up. In normal usage, I assume one would ensure there’s plenty of backing storage available to service multiple volumes, that individual volumes wouldn’t generally be expected to get more than a certain percentage full, and that some sort of monitoring and/or alerting would be in place to warn of disk pressure.
With four nodes, each with a single 8GB disk, and Longhorn apparently reserving 2.33GB by default on each disk, that means no Longhorn volume can physically store more than a bit over 5.5GB of data (see the Size column in the previous screenshot). Given that the default setting for Storage Over Provisioning Percentage is 200, we’re actually allowed to allocate up to a bit under 11GB.
So I went and created a 10GB volume, attached that to the master node, created a filesystem on it, and wrote a whole lot of zeros to it:
master:~ # mkfs.ext4 /dev/sda mke2fs 1.46.5 (30-Dec-2021) [...] master:~ # mount /dev/sda /mnt master:~ # df -h /mnt Filesystem Size Used Avail Use% Mounted on /dev/sda 9.8G 24K 9.3G 1% /mnt master:~ # dd if=/dev/zero of=/mnt/big-lot-of-zeros bs=1M status=progress 2357198848 bytes (2.4 GB, 2.2 GiB) copied, 107 s, 22.0 MB/s
While that dd was running, I was able to see the used space of the replicas increasing in the Longhorn UI:
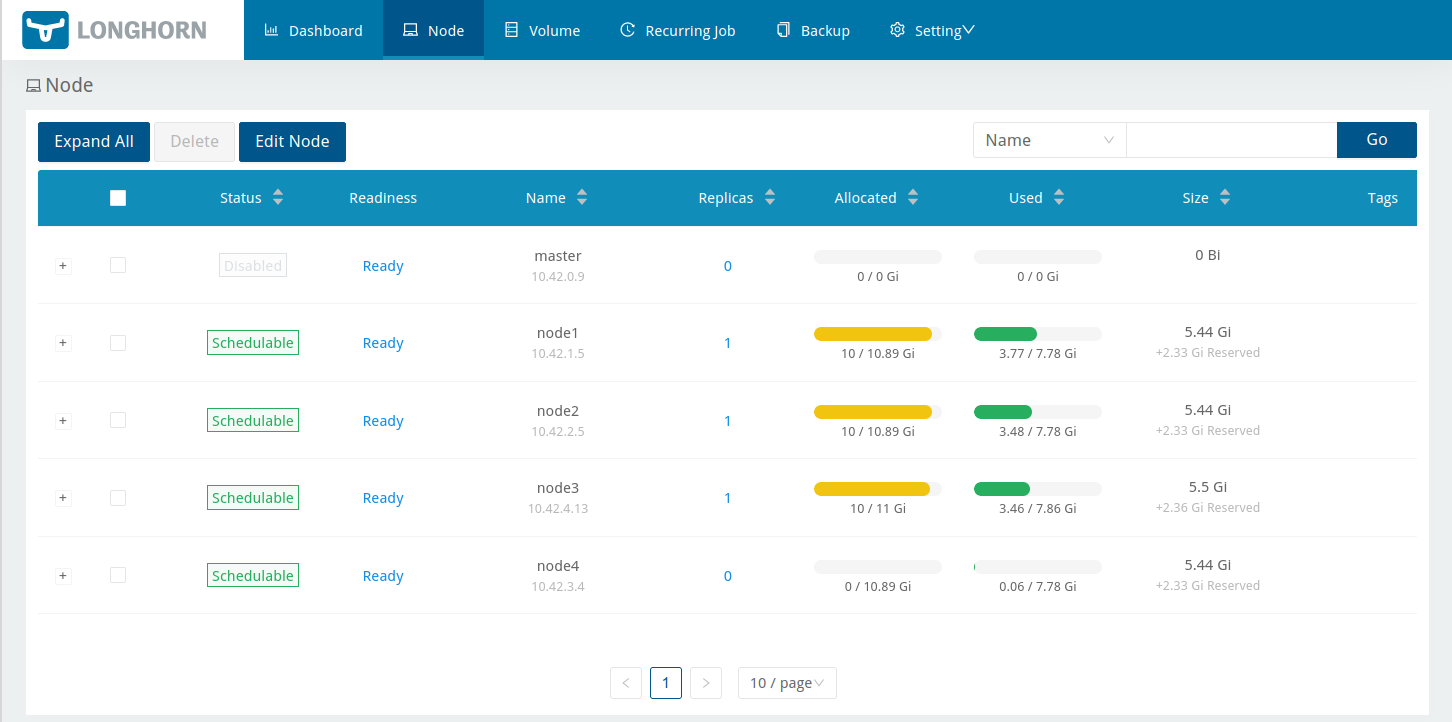
After a few more minutes, the dd stalled…
master:~ # dd if=/dev/zero of=/mnt/big-lot-of-zeros bs=1M status=progress 9039773696 bytes (9.0 GB, 8.4 GiB) copied, 478 s, 18.9 MB/s
…there was a lot of unpleasantness on the master node’s console…
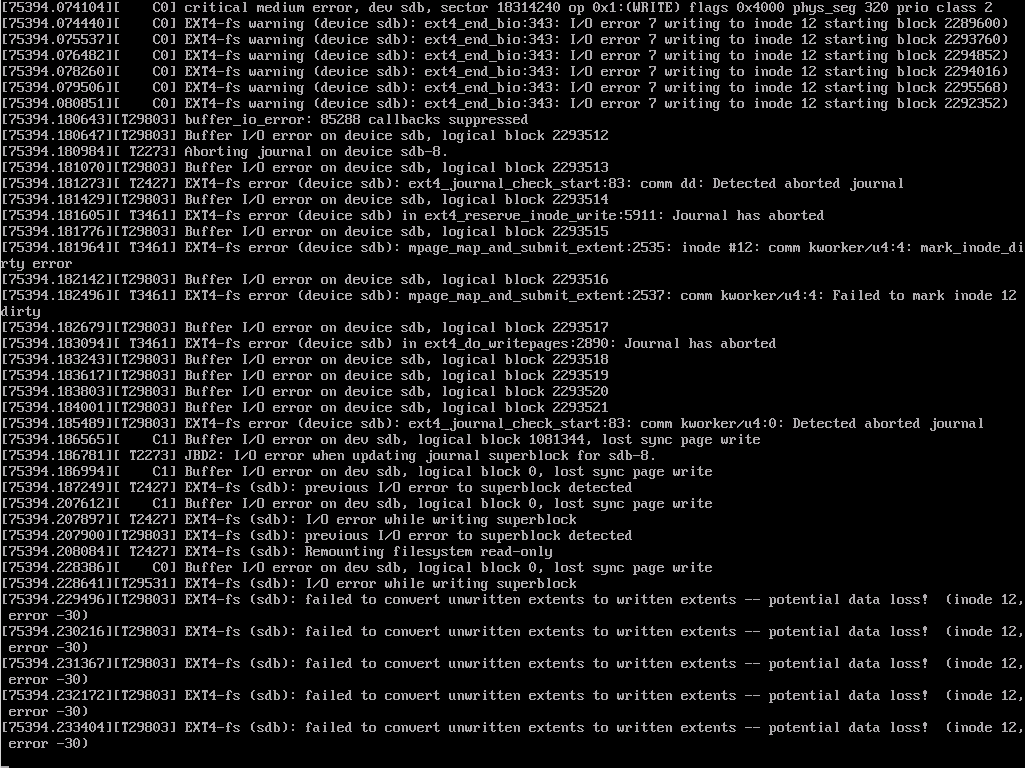
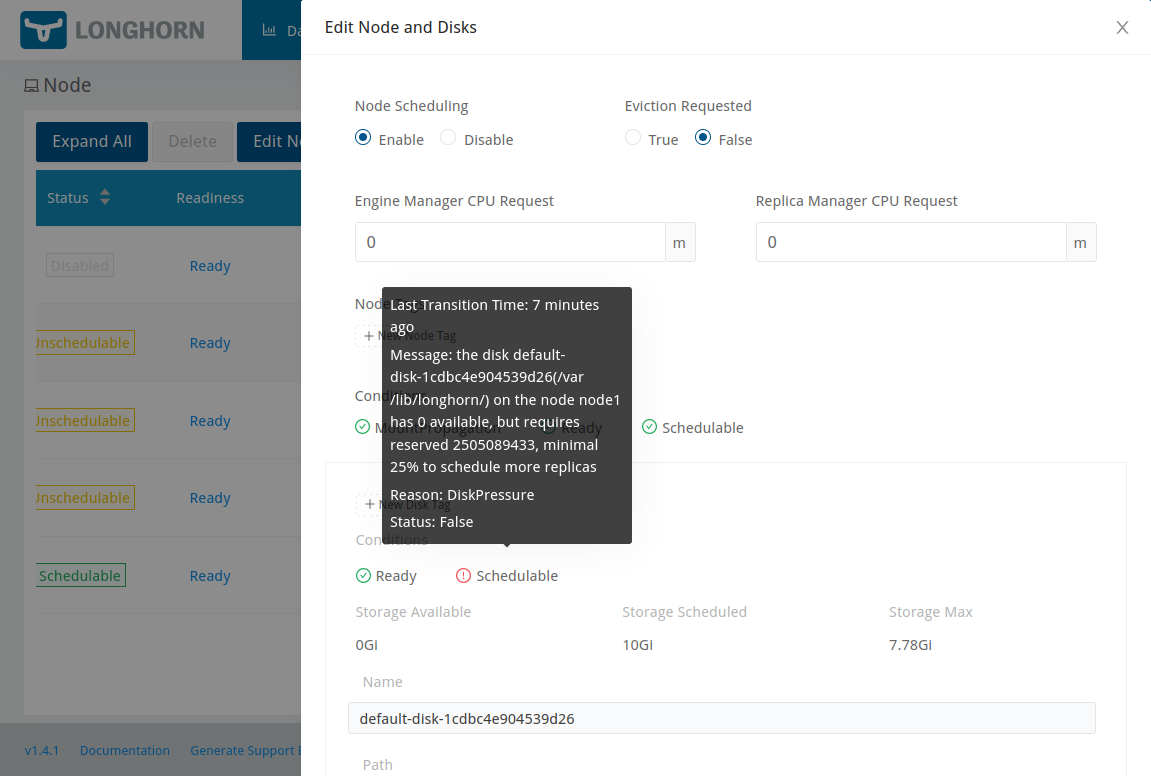
…the replicas became unschedulable due to lack of space…
…and finally the volume faulted:
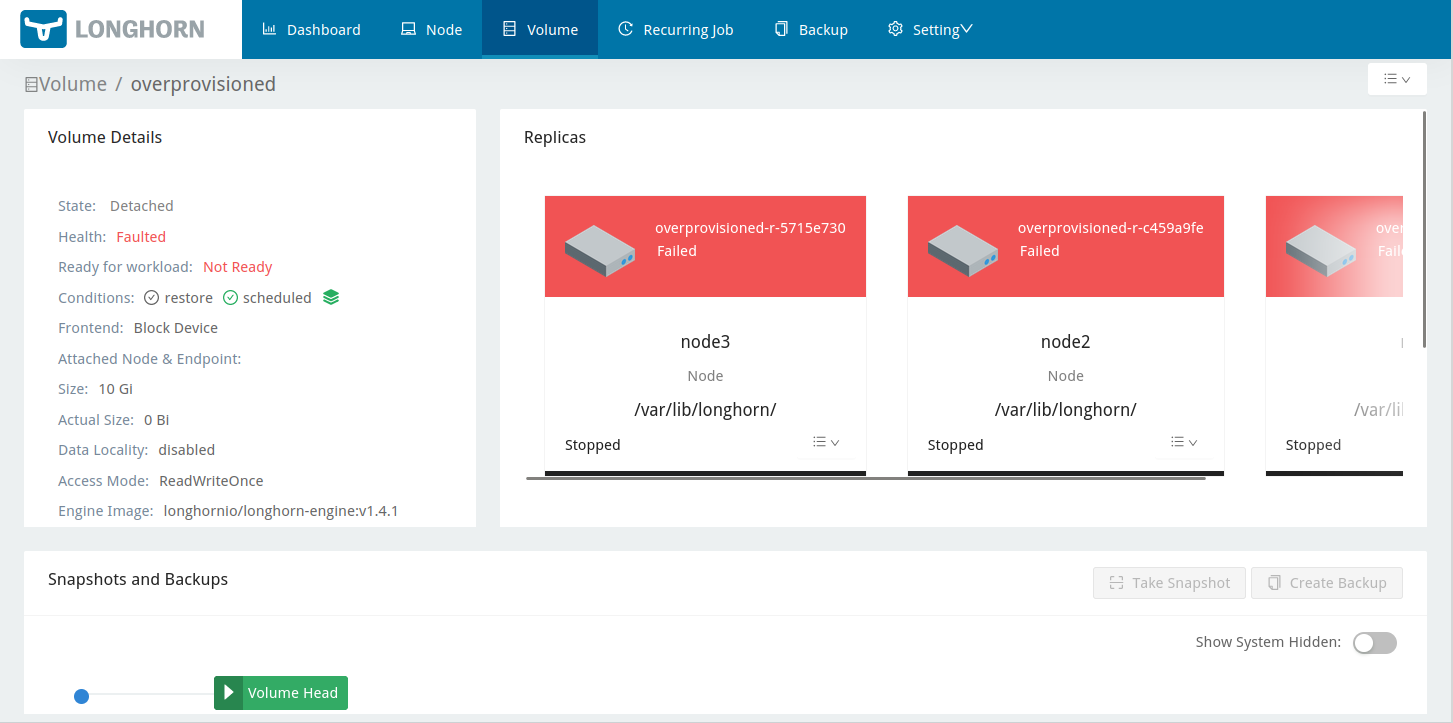
Now what?
It turns out that Longhorn will actually recover if we’re able to somehow expand the disks that store the replicas. This is probably a good argument for backing Longhorn with an LVM volume on each node in real world deployments, because then you could just add another disk and extend the volume onto it. In my case though, given it’s all VMs and virtual block devices, I can actually just enlarge those devices. For each node then, I:
- Shut it down
- Ran
qemu-img resize /var/lib/libvirt/images/k3s-longhorn_$NODE-vdb.qcow2 +8G - Started it back up again and ran
resize2fs /dev/vdbto take advantage of the extra disk space.
After doing that to node1, Longhorn realised there was enough space there and brought node1’s replica of my 10GB volume back online. It also summarily discarded the other two replicas from the still-full disks on node2 and node3, which didn’t yet have enough free space to be useful:
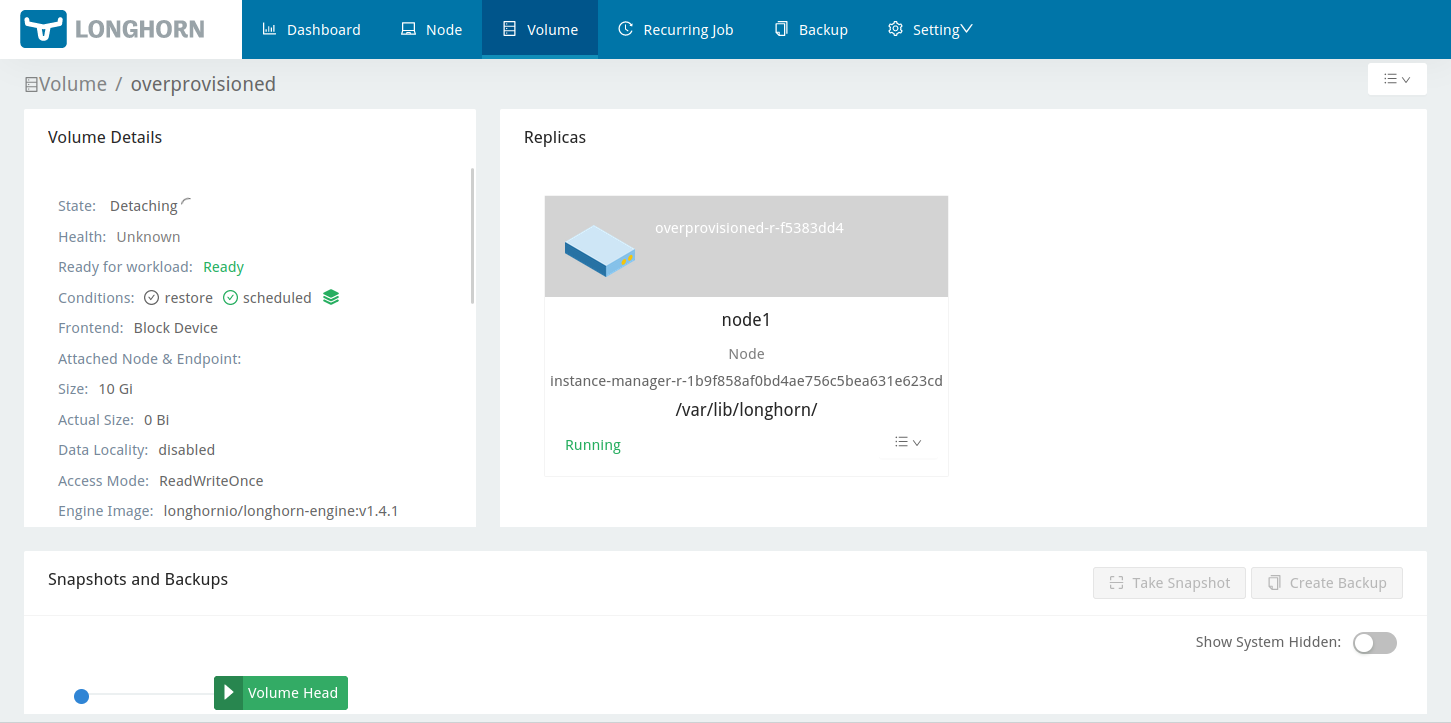
As I repeated the virtual disk expansion on the other nodes, Longhorn happily went off and recreated the missing replicas:
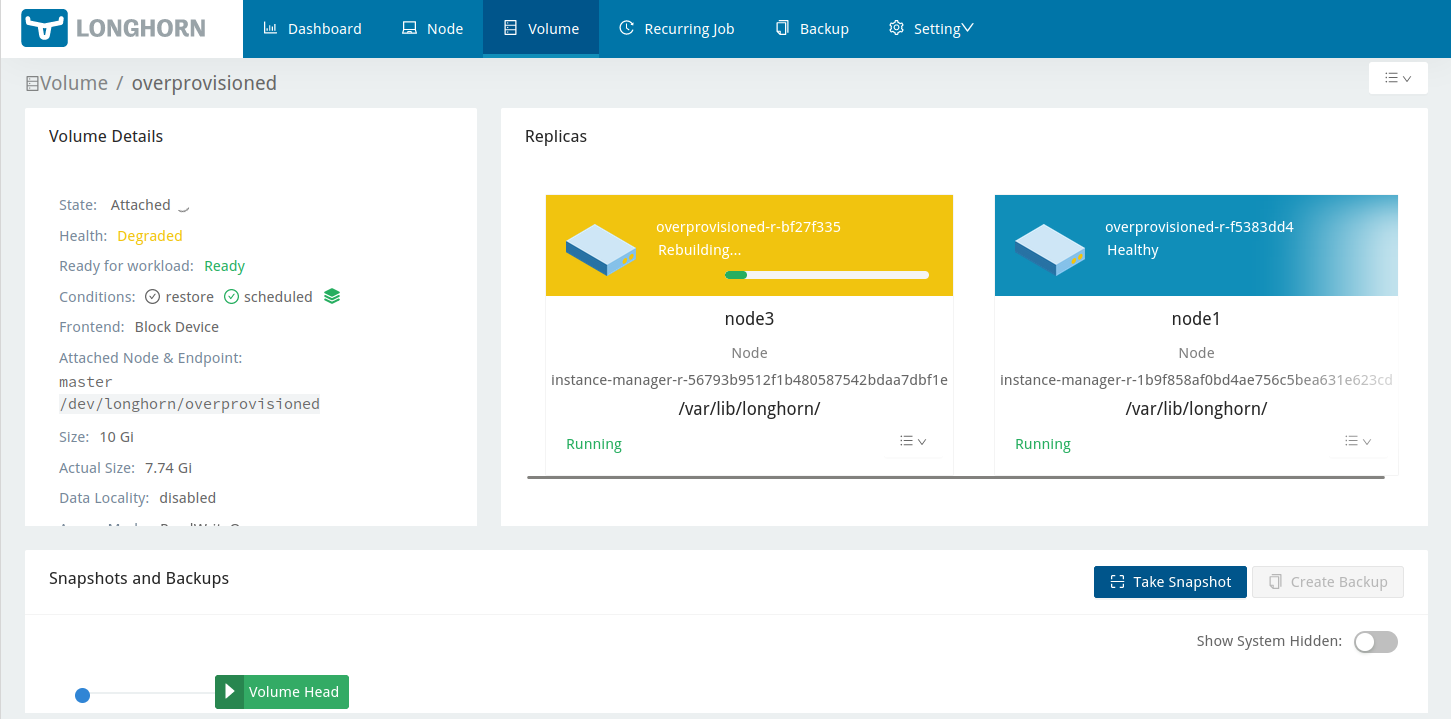
Finally I could re-attach the volume to the master node, and have a look to see how many of my zeros were actually written to the volume:
master:~ # cat /proc/partitions major minor #blocks name 254 0 44040192 vda 254 1 2048 vda1 254 2 20480 vda2 254 3 44016623 vda3 8 0 10485760 sda master:~ # mount /dev/sda /mnt master:~ # ls -l /mnt total 7839764 -rw-r--r-- 1 root root 8027897856 May 3 04:41 big-lot-of-zeros drwx------ 2 root root 16384 May 3 04:34 lost+found
Recall that dd claimed to have written 9039773696 bytes before it stalled when the volume faulted, so I guess that last gigabyte of zeros is lost in the aether. But, recall also that this isn’t really a fair test – one overprovisioned volume deliberately being quickly and deliberately filled to breaking point vs. a production deployment with (presumably) multiple volumes that don’t fill quite so fast, and where one is hopefully paying at least a little bit of attention to disk pressure as time goes by.
It’s worth noting that in a situation where there are multiple Longhorn volumes, assuming one disk or LVM volume per node, the replicas will all share the same underlying disks, and once those disks are full it seems all the Longhorn volumes backed by them will fault. Given multiple Longhorn volumes, one solution – rather than expanding the underlying disks – is simply to delete a volume or two if you can stand to lose the data, or maybe delete some snapshots (I didn’t try the latter yet). Once there’s enough free space, the remaining volumes will come back online. If you’re really worried about this failure mode, you could always just disable overprovisioning in the first place – whether this makes sense or not will really depend on your workloads and their data usage patterns.
All in all, like I said earlier, I think Longhorn behaved pretty well given what I did to it. Some more information in the event log could perhaps be beneficial though. In the UI I can see warnings from longhorn-node-controller e.g. “the disk default-disk-1cdbc4e904539d26(/var/lib/longhorn/) on the node node1 has 3879731200 available, but requires reserved 2505089433, minimal 25% to schedule more replicas” and warnings from longhorn-engine-controller e.g. “Detected replica overprovisioned-r-73d18ad6 (10.42.3.19:10000) in error“, but I couldn’t find anything really obvious like “Dude, your disks are totally full!”
Later, I found more detail in the engine manager logs after generating a support bundle ([…] level=error msg=”I/O error” error=”tcp://10.42.4.34:10000: write /host/var/lib/longhorn/replicas/overprovisioned-c3b9b547/volume-head-003.img: no space left on device”) so the error information is available – maybe it’s just a matter of learning where to look for it.